Integration
This site serves as a repository for the course materials provided on the second day of the course The Hitchhiker’s Guide to scRNA-seq (08-12/07/2024, iMM, Lisbon, Portugal), which focuses on the integration of single-cell RNA sequencing data.
The course materials utilize minimalistic, publicly available scRNA-seq datasets to evaluate the performance of various integration methods across three tasks: (1) cross-tissue, (2) biological conditions, and (3) cell lines. The course addresses the challenges of integration, highlighting the strengths and weaknesses of different methods applied to these tasks. Additionally, a practical example of reference mapping is demonstrated by classifying and projecting PBMCs from two COVID-19 patients onto a previously annotated PBMC reference.
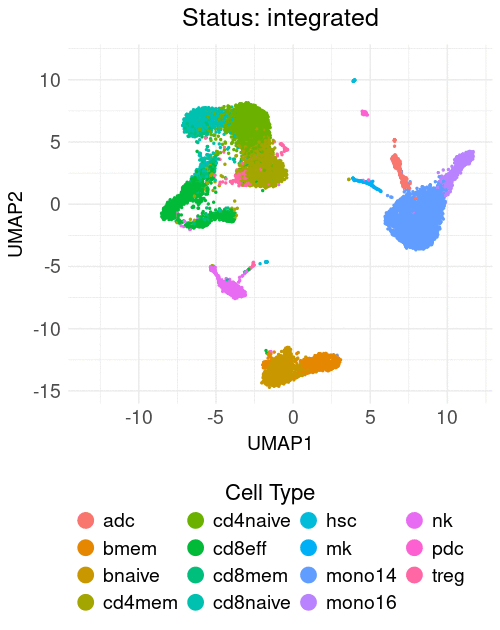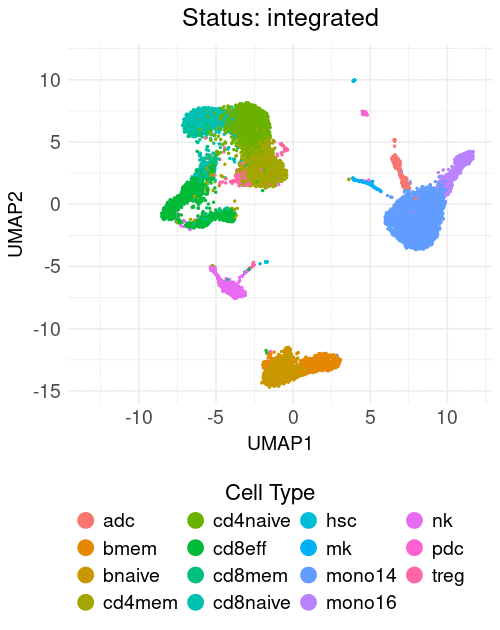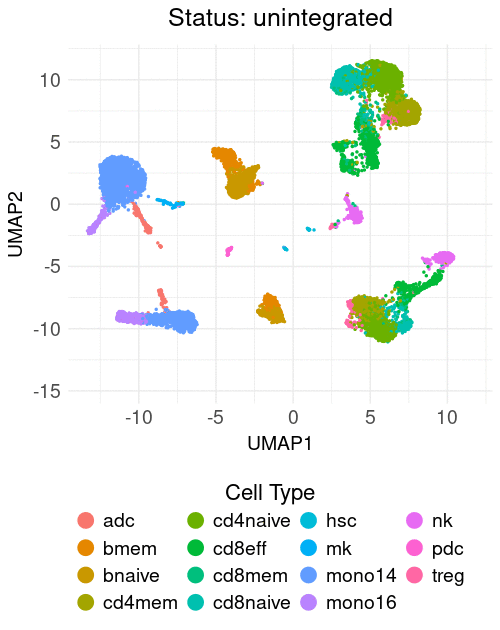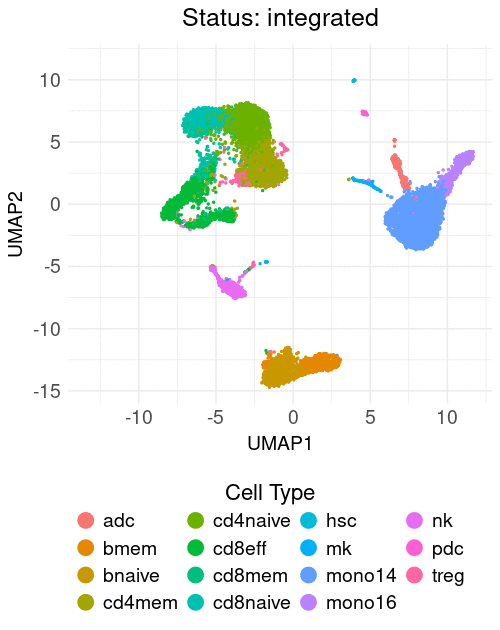
Table of contents
Outline
The timeline for the second day of the course (09/07/2024):
-
1st morning session: introduction to integration (presentation)
-
2nd morning session: introduction to the practical session & hands-on (notebooks 1-2)
-
1st afternoon session: continue hands-on (notebooks 2-3) & wrap-up integration analysis sessions
-
2nd afternoon session: hands-on (notebook no. 4) & session’s wrap up/conclusions
Course materials
Introduction to integration of scRNA-seq data:
-
theoretical: presentation
-
hands-on: presentation
The course materials include four independent data analysis tasks:
-
Cross-tissue integration task
-
main goal: evaluate the performance of different integration methods for a cross-tissue integration task.
-
learning objectives: joint and integrative scRNA-seq data analysis with
Seurat. -
data (
pbmc3k_panc8.rds): aSeuratR object of two data sets - 3k human PBMCs from 10X Genomics and pancreatic islets from indrop1 - retrieved fromSeuratDatapackage (v.0.2.2.9001). -
R markdown notebook:
01_cross_tissue_task.Rmd -
vignette: 01_cross_tissue_task.html
-
estimated computing time: <7 min
-
estimated memory: <8 GB
-
-
Ifnb stimulated integration task
-
main goal: evaluate the performance of different integration methods for an integration analysis involving different biological conditions.
-
learning objectives: joint and integrative scRNA-seq data analysis with
Seurat. -
data (
ifnb.rds): aSeuratR object of two human PBMCs data sets - resting/control and interferon-stimulated - retrieved from the R package SeuratData (v.0.2.2.9001). -
R markdown notebook:
02_ifnb_stimulated_task.Rmd -
vignette: 02_ifnb_stimulated_task.html
-
estimated computing time: <4 min
-
estimated memory: <8 GB
-
-
Cell lines integration task
-
main goal: evaluate the performance of different integration methods for the integration of cell lines with different proportions.
-
learning objectives: joint and integrative scRNA-seq data analysis with
Seurat. -
data (
jurkat.rds): aSeuratR object comprising three data sets - Jurkat, HEK293T and Jurkat:HEK293T (50:50) - retrieved from 10X genomics and published by Zheng et al., 2017. -
R markdown notebook:
03_cell_lines_task.Rmd -
vignette: 03_cell_lines_task.html
-
estimated computing time: <4 min
-
estimated memory: <8 GB
-
-
COVID reference-mapping task
-
main goal: learn how to perform and evaluate reference-mapping analysis of scRNA-seq data.
-
learning objectives: perform and evaluate reference-mapping of scRNA-seq data with
SeuratandAzimuth. -
data (
covid.rds): aSeuratR object of a COVID-19 PBMCs data set from Guo et al., 2020 retrieved from cziscience -
R markdown notebook:
04_covid_refmap_task.Rmd -
vignette: 04_covid_refmap_task.html
-
estimated computing time: <4 min
-
estimated memory: <8 GB
-
The course material for these projects can be found in the following GitHub repository (under the folder course): https://github.com/elolab/Hitchhikers_Guide_scRNAseq_course.
Download the GitHub repository by typing in the terminal:
git clone https://github.com/elolab/Hitchhikers_Guide_scRNAseq_course.git
Alternatively download the GitHub repository by clicking under the Download ZIP icon (decompress the folder).
All the data used has been deposited as Seurat R objects in Zenodo: https://doi.org/10.5281/zenodo.12620772.
Software requirements
The following software is required in order to reproduce the analyses comprised in the notebooks above (check first if you have these packages installed before try to installing them):
R programming language(>=v.4.1.0): https://www.r-project.org/
RStudio(v.1.4.1717© 2009-2021 RStudio, PBC - any version): https://posit.co/download/rstudio-desktop/
-
Seurat(v.5.1.0): https://satijalab.org/seurat/articles/install_v5- command:
install.packages("Seurat")
- command:
-
remotes(v.2.5.0 - any version): https://cran.r-project.org/web/packages/remotes/index.html- command:
install.packages("remotes")
- command:
-
SeuratWrappers(v.0.3.2): https://github.com/satijalab/seurat-wrappers- command:
remotes::install_github("satijalab/seurat-wrappers", quiet = TRUE)
- command:
-
Azimuth(v.0.5.0): https://github.com/satijalab/azimuth- command:
remotes::install_github("satijalab/azimuth", quiet = TRUE)
- command:
-
patchwork(>=v.1.2.0): https://patchwork.data-imaginist.com- command:
install.packages("patchwork")
- command:
-
dplyr(>=v.1.1.4): https://dplyr.tidyverse.org- command:
install.packages("dplyr")
- command:
-
scIntegrationMetrics(v.1.1): https://github.com/carmonalab/scIntegrationMetrics- command:
remotes::install_github("carmonalab/scIntegrationMetrics")
- command:
-
ComplexHeatmap(v.2.15.4 - any version): https://jokergoo.github.io/ComplexHeatmap-reference/book- command:
remotes::install_github("jokergoo/ComplexHeatmap")
- command:
-
BiocManager(v.1.30.23): https://www.bioconductor.org/install- command:
install.packages("BiocManager")
- command:
-
zellkonverter(v.1.4.0): https://github.com/theislab/zellkonverter- command:
BiocManager::install("zellkonverter")
- command:
-
matrixStats(v.1.1.0): https://cran.rstudio.com/web/packages/matrixStats- command:
remotes::install_version("matrixStats", version = "1.1.0")
- command:
Alternatively you can install docker and pull the image elolabfi/imm_scrnaseq_course (7.7 Gb) from DockerHub. This image has all the software mentioned above installed as well as the data, scripts and notebooks to run the materials.
Ubuntu
In Ubuntu, you can install docker following these instructions: https://docs.docker.com/desktop/install/ubuntu
Once installed, you can run the following command in the terminal after creating the folder results:
mkdir results
docker run --rm -ti -e PASSWORD=imm -p 8787:8787 -v $PWD/results:/home/rstudio/results elolabfi/imm_scrnaseq_course:latest
Then, go to your browser and type:
http://localhost:8787
# user: rstudio
# password: imm
Other OS
See how to install docker for other OS: https://www.docker.com/products/docker-desktop
Target audience
Researchers who want to learn how to perform integration and reference-mapping analyses of single-cell-RNA-seq data.
Pre-requisites
The course materials are delivered as R markdown notebooks which can be reproduced with basic-level knowledge of R programming language. The participants may benefit from medium-level knowledge of R to explore more in-depth some analyses and familiarity with Seurat object and functionality.
Instructor
António Sousa (ENLIGHT-TEN+ PhD student at the Medical Bioinformatics Centre, TBC, University of Turku & Åbo Akademi)
Contact: aggode@utu.fi
Disclaimer
All the data used along each project notebook was made public elsewhere by the respective authors and it has been properly referenced in each project (proper links were provided along each project notebook). The data and tools chosen to address the topic(s) of each project notebook reflect only my personal experience/knowledge and they were chosen to highlight particular aspects that I consider important. The results generated and explored within each project notebook have just the general purpose of give a brief introduction to the topics addressed in each project and do not aim, at any point, to reproduce or question neither the approaches taken nor the main findings published along with the data sets used herein.
Acknowledgements
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No.: 955321

Shield: ![]()
This work is licensed under a Creative Commons Attribution 4.0 International License.
